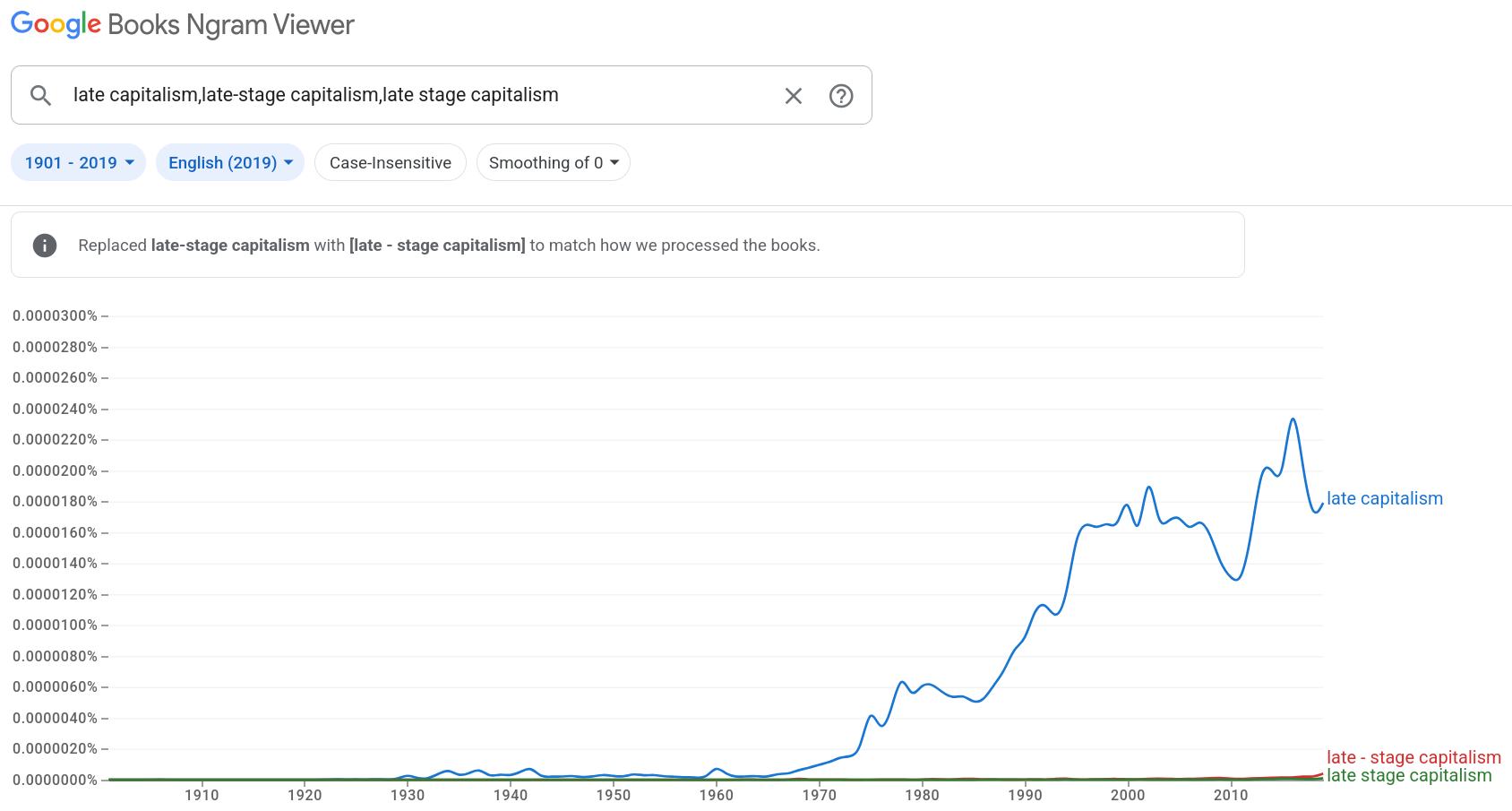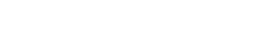

Tariffs Cause (Price-)Inflation
28 July 2025Quite a few economists who argue in favor of free international trade none-the-less claim that tariffs do not cause inflation
.
A small share of these economist argue quite terribly, by treating one of the original definitions of inflation
as if it is the only permissible definition.
Under those original definitions, inflation
referred, depending upon just who was using the term, to increases in the stock of money, to such increases effected by debasement or by the issuance of debt instruments, or to increases in the stock of money not matched by general increases in supplies of commodities.
The general public was so used to the idea that increases in the money stock would lead to general increases in prices that inflation
came to be treated as if meaning a general increase in prices. An interesting study might be written on how this secondary, operational definition came to be primary; certainly, removing what had been the primary definition from popular consciousness made it easier for policy-makers to ignore the ideas that increases in the money stock would lead to general increases in prices and that general increases in prices were likely to have been caused by increases in the money stock. But, as unfortunate as this change in definition may have been, the fact remains that, not only in popular discourse but in the discourse of economists, the most common use of inflation
now is in reference to a general increase in prices.
If the idea of a general increase in prices were itself incoherent, then one might still have a basis for rejecting attempts to use inflation
thus. But, as things stand, attempts to argue against the conceptual content of claims about price-inflation by insisting that inflation
can only mean some sort of increase in the money stock, even when the term has been used by one's opponent, are abusive.
(Mind you that I advocate avoiding use of the bald term inflation
to refer to general increases in prices.)
The larger share of economists tolerate or accept the use of inflation
to mean price-inflation, but none-the-less argue that price-inflation is not amongst the ills caused by tariffs.
These economists quite rightly distinguish an increase in the price of one good from a general increase in prices, and likewise increases in the prices of many but not most goods from a general increase in prices; but these economist do not attend properly to the elasticity of the commodities upon which tariffs are placed, and especially to the cross-price elasticities of other commodities. It is as if these economists imagine money to be reallocated with no over-all change in the quantities of commodities purchased.
If the price of some commodity is increased, we must infer that people make one of three choices,
- buy the same quantity of the commodity, but buy less of other commodities, or
- expend just as much money on the commodity, but buy less of it, or
- shift some of their expenditures to buying other resources, buying less or none of the commodity the price of which increased.
Economically rational agents — and we must suppose real-world people to behave in a manner that is approximated by economic rationality — exchange their resources, including money, for the ends most useful to them. Thus,
- if they buy less of other commodities, they lose the marginal uses of those other commodities;
- if they buy less of the original commodity, they lose the original marginal uses of that commodity; and
- if they move some or all of their money to purchases of other commodities, these must be commodities that provided less valuable marginal uses (at the new level of expenditure) than did the original commodity (at the prior level of expenditure).
No matter which the sort of the choice, usefulness is lost as a consequence of the price increase.
To the extent that the commodities are factors of production — and, ultimately, all commodities are factors of production, though some quite neglibily — productivity is reduced. If we may adopt the metaphor in which multipliers have meaning, then we may say that, ceteris paribus, an increase in the cost of any resource has a multiplier of less than 1. If a resource has significant application across many productive processes, or significant application to some productive process an output of which in turn has significant application across many productive processes, then the loss of productivity will have wide-spread significance.
Recall, now, that M · ν = Σ (pi · qi) where M is the quantity of money, ν is the average rate at which the monetary unit is exchanged in trade, pi is the price of the i-th commodity, and qi is the time-rate at which quantities of the i-th commodity are exchanged. A general loss of productivity results in a general decrease in quantities supplied of the various commodities. Unless the money supply or velocity are correspondingly decreased, prices must generally increase. No mechanism for decreasing the money supply is typically entailed in the increase of the price of a commodity. The technologic aspect of moving money will become more costly, which has a slowing effect on the average rate at which the monetary unit is exchanged, but certainly not usually so as to fully offset the general loss of commodities. We should expect a general increase in prices.
Tariffs, then, cause a price-inflation, by way of their effects on production. The inflationary effect of a tariff on some commodities will be so negligible as to be indetectable; the effect of tariffs on other commodities may be profound.
![[image of mathematic formula]](wp-content/uploads/2024/09/AP11.png) This refactoring is mathematically trivial, exploiting two automorphisms, but exhibits the principle more elegantly.
This refactoring is mathematically trivial, exploiting two automorphisms, but exhibits the principle more elegantly.![[image of mathematic formula]](wp-content/uploads/2024/08/A9.png) may be more simply stated as
may be more simply stated as ![[image of mathematic formula]](wp-content/uploads/2024/08/AP7.png)
![[two lognormal distributions of equal median but of different variance]](wp-content/uploads/2024/08/equal_median_0.png) For both Population A and Population B, the median
For both Population A and Population B, the median![[two lognormal distributions of equal median but of different variance]](wp-content/uploads/2024/08/equal_median_1.png) Population B2
Population B2 ![[two lognormal distributions of equal mean but of different variance]](wp-content/uploads/2024/08/equal_mean_1.png) has the same variance as Population B, but the same arithmetic mean (rather than median) as Population A. Again, even though the center is, by some measure, the same for both populations, more members of the population of greater variance are below some some measure, and more members of that same population are above some measure.
has the same variance as Population B, but the same arithmetic mean (rather than median) as Population A. Again, even though the center is, by some measure, the same for both populations, more members of the population of greater variance are below some some measure, and more members of that same population are above some measure.![[two lognormal distributions of different mean and variance]](wp-content/uploads/2024/08/higher_center.png) And even if a population has a lower center than Population A, if it has a greater variance then it will dominate the higher range of measures beyond some measure.
And even if a population has a lower center than Population A, if it has a greater variance then it will dominate the higher range of measures beyond some measure. ![[two lognormal distributions of different mean and variance]](wp-content/uploads/2024/08/lower_center.png)
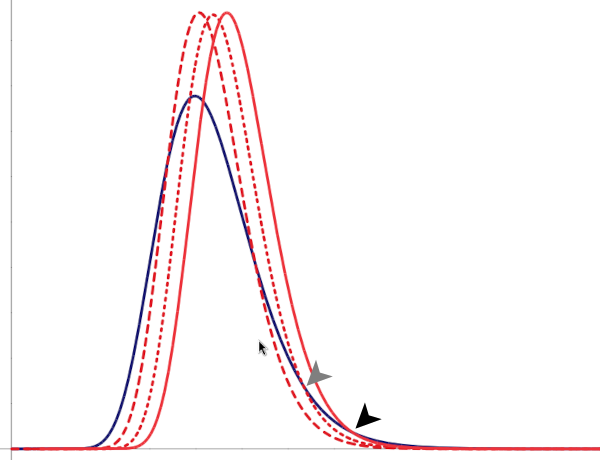 as the relative outcomes for most members of the population of greater variance fall increasingly below those of the population of less variance — at previously targetted levels the population of lower variance comes to enjoy greater social success than does the population of greater variance. And notice that the population of greater variance necessarily still dominates above some value, albeït that the value increases as the institutional thumb comes down ever harder in a misguided attempt to match the upper tails of the distribution.
as the relative outcomes for most members of the population of greater variance fall increasingly below those of the population of less variance — at previously targetted levels the population of lower variance comes to enjoy greater social success than does the population of greater variance. And notice that the population of greater variance necessarily still dominates above some value, albeït that the value increases as the institutional thumb comes down ever harder in a misguided attempt to match the upper tails of the distribution.
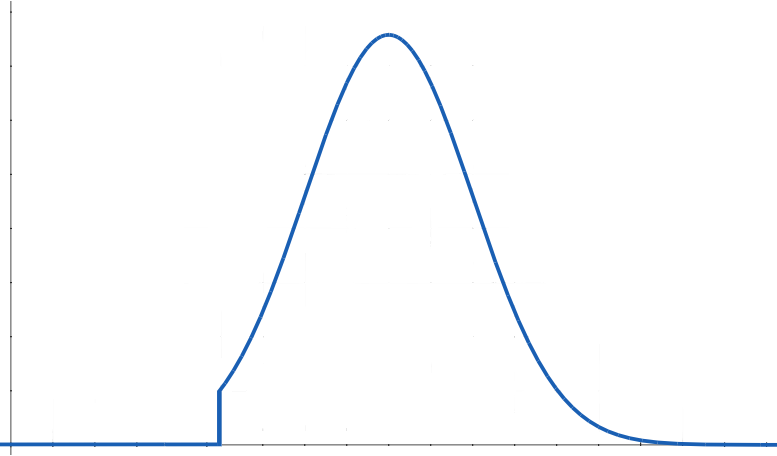 usually doesn't make a great deal of sense, because few people will even be near the lower bound, rather than a fair number at it or just barely above it.
usually doesn't make a great deal of sense, because few people will even be near the lower bound, rather than a fair number at it or just barely above it.