
Virtual Shelving
Sunday, 19 June 2022[This entry was revised and expanded on 2022:07/07.]
I am always uncomfortable with the process of organizing books and articles on shelves or in boxes. I desire to have them grouped by each author and by each subject of interest; these desires cannot be reconciled without having multiple copies of each book and of each article, which multiplicity I cannot afford.
Electronic copies are a different matter. Even without multiple copies, symbolic links, which I discussed in a previous entry, make it possible effectively to list the same file in multiple directories. Hereïn, I'll explain the principle structure that I use for organizing documents, and I'll present some small utilities that facilitate creating and maintaining that structure on POSIX-compliant file systems. This structure is not as fine-grained as might be imagined, but it strikes a balance appropriate to my purposes. (For a more sophisticated system one should employ an application storing and retrieving documents mediated by a cataloguing relational database.)
As with many systems, mine have each a directory named
. Its two subdirectories relevant to this discussion are DocumentsAuthors and Subjects. 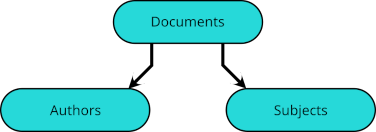
The entries in Subjects are subdirectories with names such as
, Economics
, Logic and Probability
, and Mathematics
. Philosophy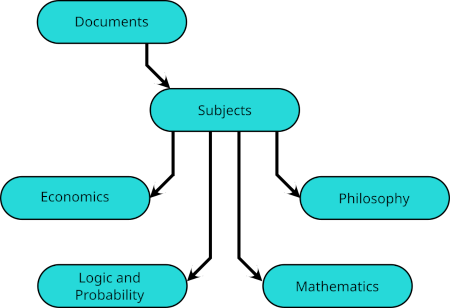
In turn, the entries in each of these are subdirectories with the names of authors. 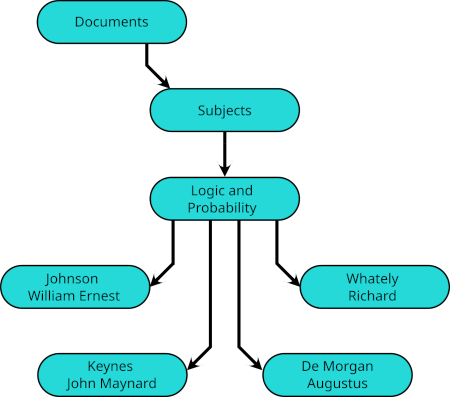
Finally, in each of these subdirectories are entries for files containing their work corresponding to the superdirectory. For example, Documents/Subjects/Logic and Probability/Johnson William Ernest/ would have entries for works by him on logic or on probability,  but his article on indifference curves would be listed instead in
but his article on indifference curves would be listed instead in Documents/Subjects/Economics/Johnson William Ernest/.
Most of the subdirectories of Authors have names corresponding to the subdirectories in the third level of the Subjects substructure, but all of these subdirectories in Authors are different directories from those in the Subjects substructure. 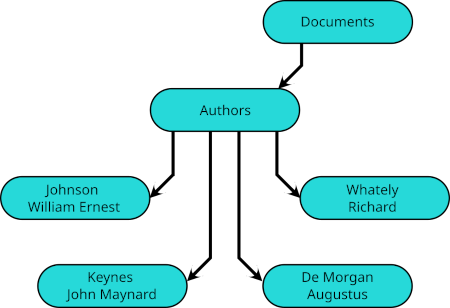
Each of most of these subdirectories of Authors lists not subdirectories nor files, but symbolic links. 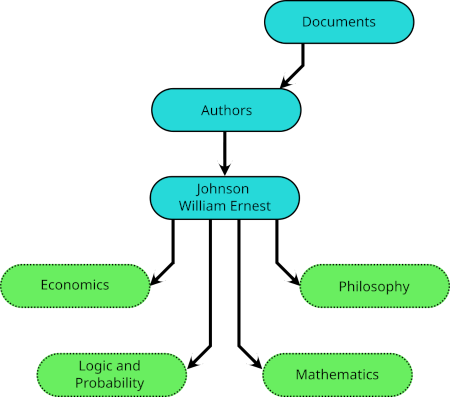 These links take their names from the subdirectories of
These links take their names from the subdirectories of Subjects, but they do not link to those subdirectories. Instead, each links to an author-specific sub-subdirectory. Thus, for example, Documents/Authors/Johnson William Ernest/Logic and Probability is a symbolic link to Documents/Subjects/Logic and Probability/Johnson William Ernest. It is as if the subject-specific collection of an author's works is the author-specific collection of works on that subject, just as it should be. 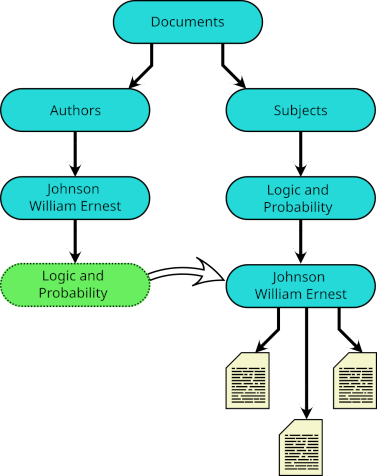
One could, instead, use the complementary organization, in which the Subjects substructure were ultimately dependent upon the Authors substructure, or use a hybrid organization in which some of the dependency flows one way and some the other. The determinant should be what is most important to preserve if the collection is copied to a file system that does not support symbolic links, as in the case of a SD card with a FAT file system.
I've sketched the principal structure, but want to note useful complications of two sorts.
The first is that symbolic links may be used to place some subjects effectively under others. For example, logic an probability fall within the scope of philosophy. As well as having a directory named
listed in Logic and ProbabilitySubjects, I have a symbolic link to it listed in Philosophy. 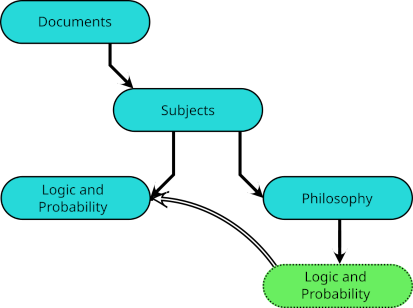 Indeed, when a subject falls within the intersection of other subjects, each may have such a symbolic link, and I have links to
Indeed, when a subject falls within the intersection of other subjects, each may have such a symbolic link, and I have links to Documents/Subjects/Logic and Probability not only in Philosophy but in Mathematics and in Economics.
The second is that symbolic links may be used effectively to list a document with multiple authors in the directory for each author. 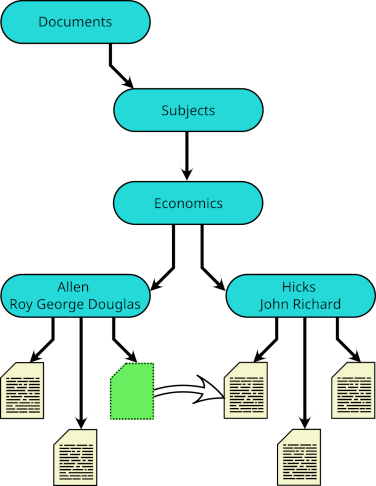 And essentially the same device may be used to classify a single document under different subjects.
And essentially the same device may be used to classify a single document under different subjects.
Although this organization is not especially fine-grained, it requires the creation of many directories and symbolic links. I've written seven utilities in Python to reduce the burden. Two of those utilities were presented in a previous 'blog entry because they can be put to more general purpose. Here, I will present five more.
(Again, these utilities are written for POSIX-compliant file systems. Windows is not POSIX-compliant. A full discussion of the relevant issues would be tedious, as would be an effort to rewrite these programs to support Windows.)
![[enlarged image of red button with central 'x' from Navigation Toolbar]](wp-content/uploads/2011/02/button_150x150j.png) actually mean? You know, that red button with the central white
actually mean? You know, that red button with the central white ![[image of red button on Navigation Toolbar]](wp-content/uploads/2011/02/button_insitu.png) What's s'posed to happen when I click on it?
What's s'posed to happen when I click on it?![[image of hexagon]](wp-content/uploads/2011/02/stop_150x150.png) It looks a lot like a stop sign, and clicking on it was a lot like stepping on a brake. The browser stopped what it was doing. That's not exactly what happens when I click on your little red-circle-with-the-eks. Now, it's as if my brakes have been redesigned by a passive-aggressive sociopath. Metaphorically speaking, the car will no longer stop before it goes into the intersection; instead, it will stop either on the other side or just in the intersection.
It looks a lot like a stop sign, and clicking on it was a lot like stepping on a brake. The browser stopped what it was doing. That's not exactly what happens when I click on your little red-circle-with-the-eks. Now, it's as if my brakes have been redesigned by a passive-aggressive sociopath. Metaphorically speaking, the car will no longer stop before it goes into the intersection; instead, it will stop either on the other side or just in the intersection.
{kind=link}