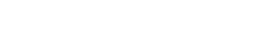

Locked Down and Probably Out
Monday, 18 December 2023
Facebook has locked-down my account, claiming suspicious activity, and demanding that I send an image of identification (such as a driver license) in order to regain access.
The claim of suspicious activity may be genuine. Some days ago, my account was one of various to which an outside party got access. Some of the victims were using two-factor authentication, and I'd done nothing that would give others access to my password, so we may be sure that Facebook itself was cracked, again. Those who broke into our accounts did not move to take control away from us, and acted in a manner that would alert us to the cracking, so the effort seems to have been a demonstration of an ability to crack into the system. (When this 'blog was hosted by Midphase, the server itself was cracked, but the crackers did no worse to the users than to leave a non-executable file in our directories. By the way, Midphase sought to gaslight me when I discovered the cracking, claiming that every damn'd victim had been individually at fault.)
I simply won't provide Meta (qua Facebook or qua Instagram or otherwise) with an image of any identification document. Such an image would present data to them that I do not want them to possess. They have been both fools and knaves, about personal information and in other ways. (I was not using two-factor authentication with Facebook exactly because I didn't want them to possess my phone number or somesuch. Prompted by a suggestion from Ray Scott Percival, some days ago I ordered a YubiKey, which is due to arrive to-morrow. I will be using it for various other accounts, and would have been using it for Facebook.)
A few years ago, I found my account similarly locked-down, but the condition was cleared after several hours, without my providing the demanded information. However, I do not expect such a reversal in this case. So I will probably forfeit my account. I will not create another.
If you have found your way here from Facebook, and want to contact me, you can find an e.mail address at the bottom either of the sidebar (when viewing the desktop
version of the site) or of the hamburger menu (when viewing the mobile
version of the site). That e.mail address is presented as a graphic (to impede 'bots). The address is an alias of one with the user ID Mc_Kiernan
, so if you use a white-list to screen your e.mail then you might want to effect a substitution.
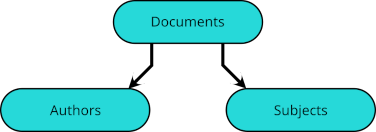
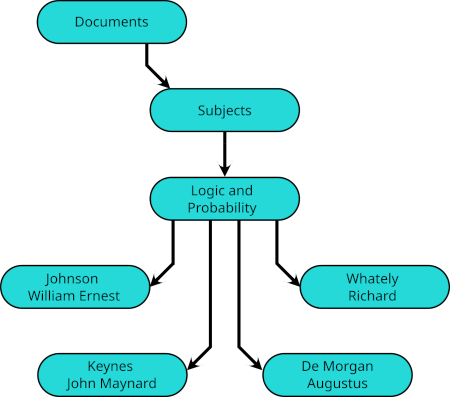
 but his article on indifference curves would be listed instead in
but his article on indifference curves would be listed instead in 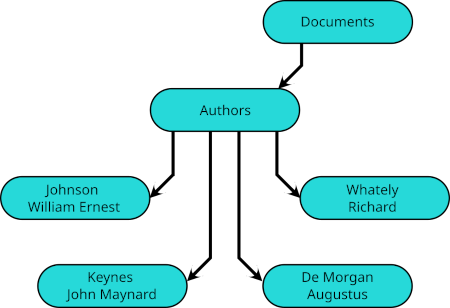
 These links take their names from the subdirectories of
These links take their names from the subdirectories of 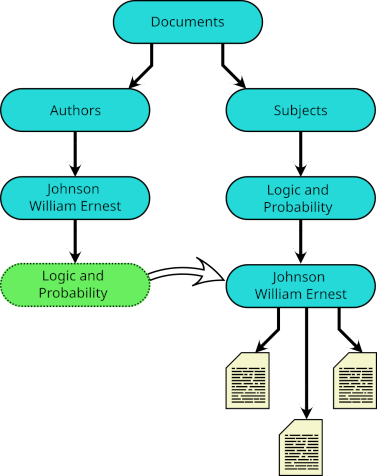
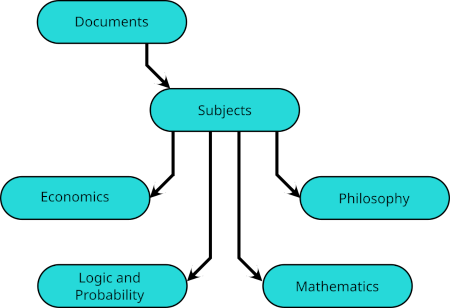
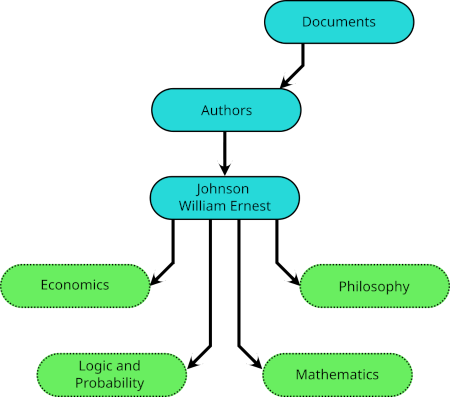
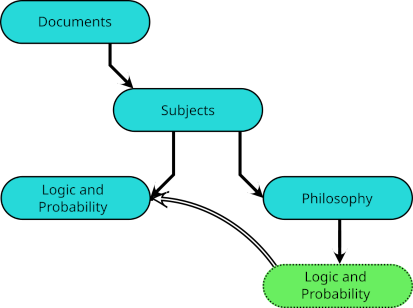 Indeed, when a subject falls within the intersection of other subjects, each may have such a symbolic link, and I have links to
Indeed, when a subject falls within the intersection of other subjects, each may have such a symbolic link, and I have links to 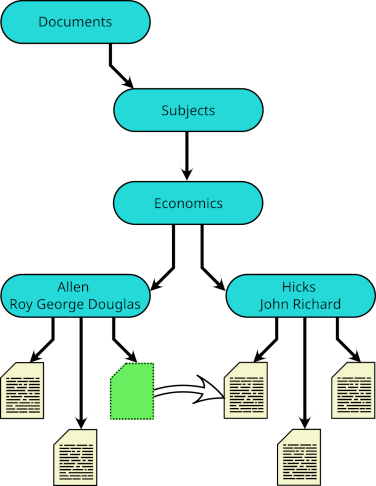 And essentially the same device may be used to classify a single document under different subjects.
And essentially the same device may be used to classify a single document under different subjects.